Bell Curves and Developer Teams
Posted on November 22, 2021
Jessica Kerr wrote a very interesting post on bell curves and engineering teams. Jessica’s point is that bell curves are for random distributions, and that when teams share information and learn from each other, they no longer can be modeled by a random distribution. I think this as true, and a valuable insight. It reminded me of a different, related observation about teams and bell curves.
Back in the 1980s, when he was applying analytics to baseball teams, Bill James argued that a common feature of the decisions made by poorly performing organizations was the assumption that baseball talent was normally distributed and could be modeled with a bell curve. This assumption about the relative availability of talent led these teams to make poor talent decisions.
Bear with me, this will tie together.
Your typical Major League Baseball executive would think about the world as though the distribution of talent looked like this — better players are further right and the height of the curve is the number of players at that level.
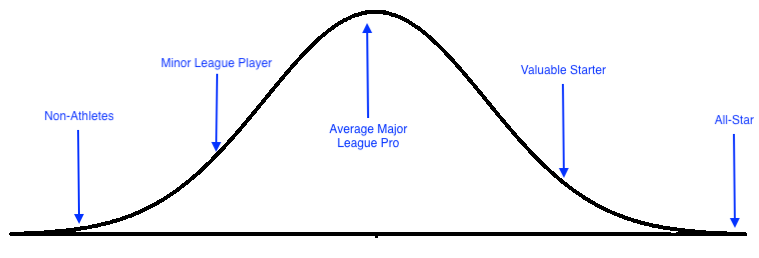
So this model suggests that the highest number of players is average, and there are fewer great players, and also fewer terrible players.
Actually, though, major league baseball players are not random. They don’t pick somebody’s name out of a hat, give them a glove and a Cubs hat and point them toward left field. Professional baseball players are the result of a thorough process designed to identify the very, very best 500 baseball players in the world. There are very few people qualified to play baseball at that level:

Professional baseball players are the extreme end of the distribution. The bell part of the curve is way off in the distance, with the part of the population that isn’t getting paid to play baseball. In this distribution, while there are few people who can play major league baseball relative to the population as a whole, there are more below average players than above average players — the hight of the curve rises steadily as the curve goes to the left.
Professional developers don’t have quite the same process as baseball players, of course, but again, they don’t just pick people at random, hand them a MacBook and point them at the Hartl Tutorial to learn Rails. The distribution curve for developers looks more like the second diagram than the first diagram.
Why do you care?
The Bill James argument is that treating skilled people like they are part of a random distribution is that doing so leads you to a false sense that talent is scarce.
If you falsely think that your talent is randomly distributed, then you think there are a few “exceptional” developers, lots of “average” developers, but then the curve goes back down and there are only a few “below average developers”. Following the logic of the bell curve, you kind of assume there are even fewer “below below average” developers.
Talent is scarce, you think.
You lead yourself to believe that there are very few available people at your most junior level, and even fewer who are skilled but even more junior. Even worse, the logic of the curve suggests that it’s exceptionally hard for a junior developer to develop – you come to feel like most of your resources developing new talent will be wasted because most of them will be in the bell of the curve and therefore, at best, just “average”.
In the baseball context, this belief led to mediocre teams placing a huge value on “proven” major leaguers with experience and a reluctance to try promising rookies. It also caused teams to focus on what developing talent can’t do, rather than supporting what developing talent can do.
And in the tech context… it’s the same thing. Organizations are unwilling to hire unproven junior devs out of the perception that there’s a huge gulf between a junior developer and a “proven” mid-level developer, or that there’s a huge percentage of “net negative” developers out there just waiting to trap unsuspecting orgs. There’s a focus on what entry-level developers can’t do, rather than on what they could do with the right organizational support.
In reality, though, on a right-tail distribution, there are still maybe only a few “exceptional” developers, but there are more “average” ones, and there are even more “slightly below average ones” and even more beyond that. In a right-tail distribution, the majority of your valuable talent is technically “below average”, and that’s fine. In a right-tail distribution, “average” is not a meaningful concept. What is meaningful is the level at which people can provide value to your team.
Following that logic, the number of developers who are at or near the level of your lowest developers is relatively high. High enough that the odds of you finding somebody at that level, should you go out and look, seem pretty good. High enough that it seems like the odds of you finding somebody out there who will grow beyond their current level also seems pretty good. The chance that somebody you hire will be able to grow and add value is much higher than is implied by the normal distribution.
We know that there are a lot of companies that are reluctant to hire junior-level developers, and I think part of the reason is this assumption that developers are in a normal distribution and “talent” — whatever talent means in this context — is rare. I don’t think this is true. I think that “talent” — again, whatever that means — is not rare, and that most engineering organizations would be better off reflecting that reality and spending more time hiring and training junior developers.

