The Road To Legacy
Posted on December 8, 2020
It occurred to me recently that two of the conference talks that I consider the best I’ve ever written never really got a very wide audience, even by the admittedly low standards of my conference talks. And I also wanted to revisit them to see if I can improve the argument.
This post comes from a talk called “The Road To Legacy is Paved With Good Intentions”, and here is the original talk video from WindyCityRails 2017.
I’m fascinated by the concept of legacy code, and in particular how code goes from being just, you know, code to being the feared legacy code.
One thing I like to do with somewhat vague terms like “legacy code” is to define them in a way that allows for some kind of objective discussion about whether a particular practice is likely to give you more of that thing or less of that thing.
The definition I use for legacy code is “code where the context of its creation has been lost”. Code is legacy if nobody around remembers why it was written, or why it was written that particular way. Often this lack of context also means that nobody remembers all the other parts of the system that the code depends on or is dependent on.
The interesting question to me is “how does code become legacy, and therefore hard to change?” and “can we do anything to stop or slow code from becoming legacy?”
The biggest problem with legacy code is that it is risky to change because it has hidden dependencies and therefore the effects of changing it are unpredictable. The code may also be hard to read, but in my experience that’s a more solvable problem. To solve a readability problem you just need to understand the code you are looking at; to solve a hidden dependency problem, you need to understand the entire system.
A hidden dependency has two parts: the “dependency” part, which is a function of the code itself, and the “hidden” part, which is a function of how the team works.
Let’s talk about dependencies first. The thing about complexity in a codebase is that it increases exponentially with the size of the codebase.
If you have a codebase with three modules (could be classes, could be systems, whatever), there are only three lines of communication between them. Four modules, six lines, six modules 15 lines, 10 modules, 45 lines, 15 modules 105 lines.
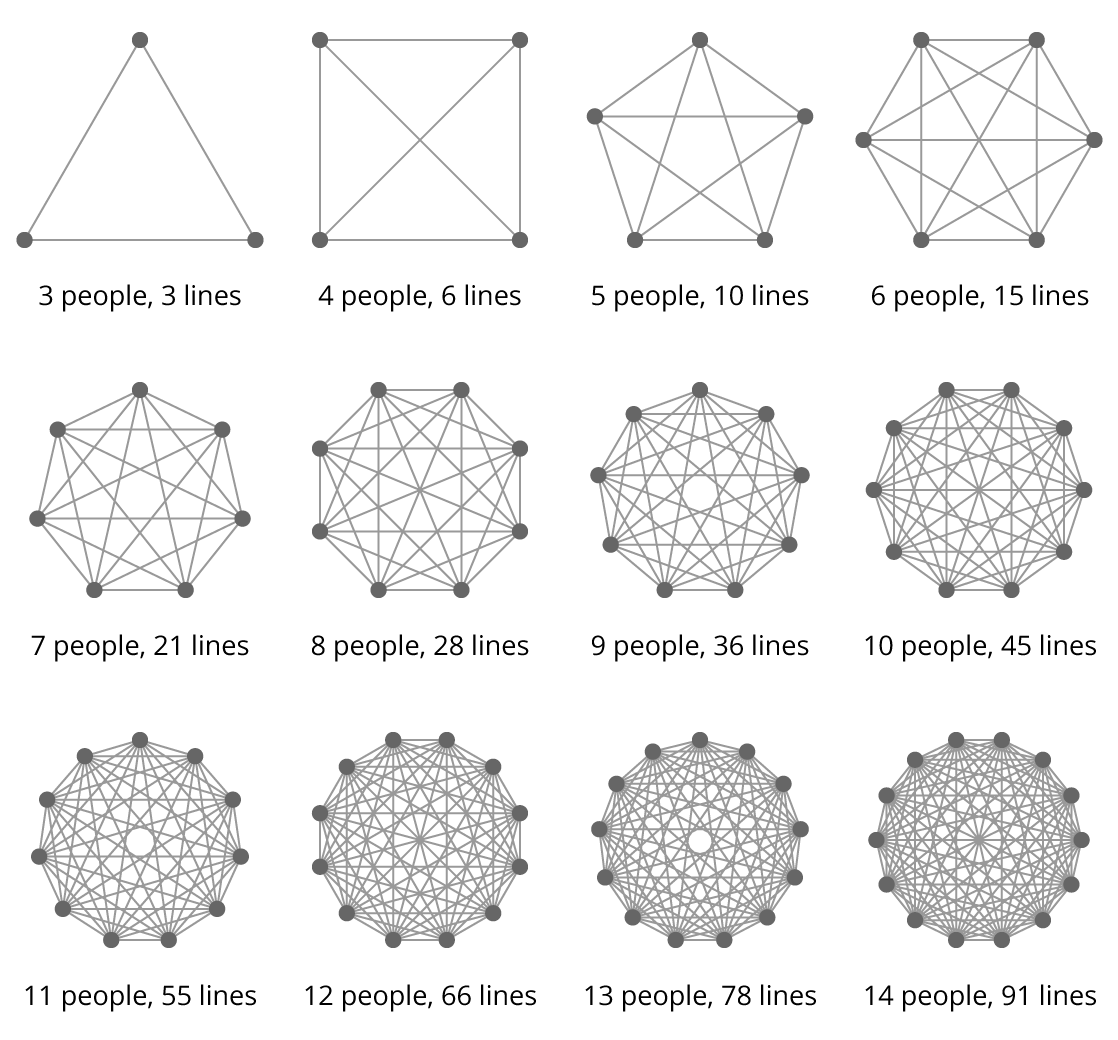
A 5x increase in the amount of modules between 3 and 15 leads to a 35x increase in the amount of communication paths.
My theory is that this exponential growth sneaks up on teams and that’s the critical reason why teams don’t adapt to complexity quickly enough.
There’s an old brain teaser about exponential growth. You have a jar with amoebas in it, the number of amoebas doubles every minute and the jar is full in an hour. When is the jar half full?
The answer is the 59 minute mark. From half full, the amoebas double again in a minute and the jar is full at the 60 minute mark.

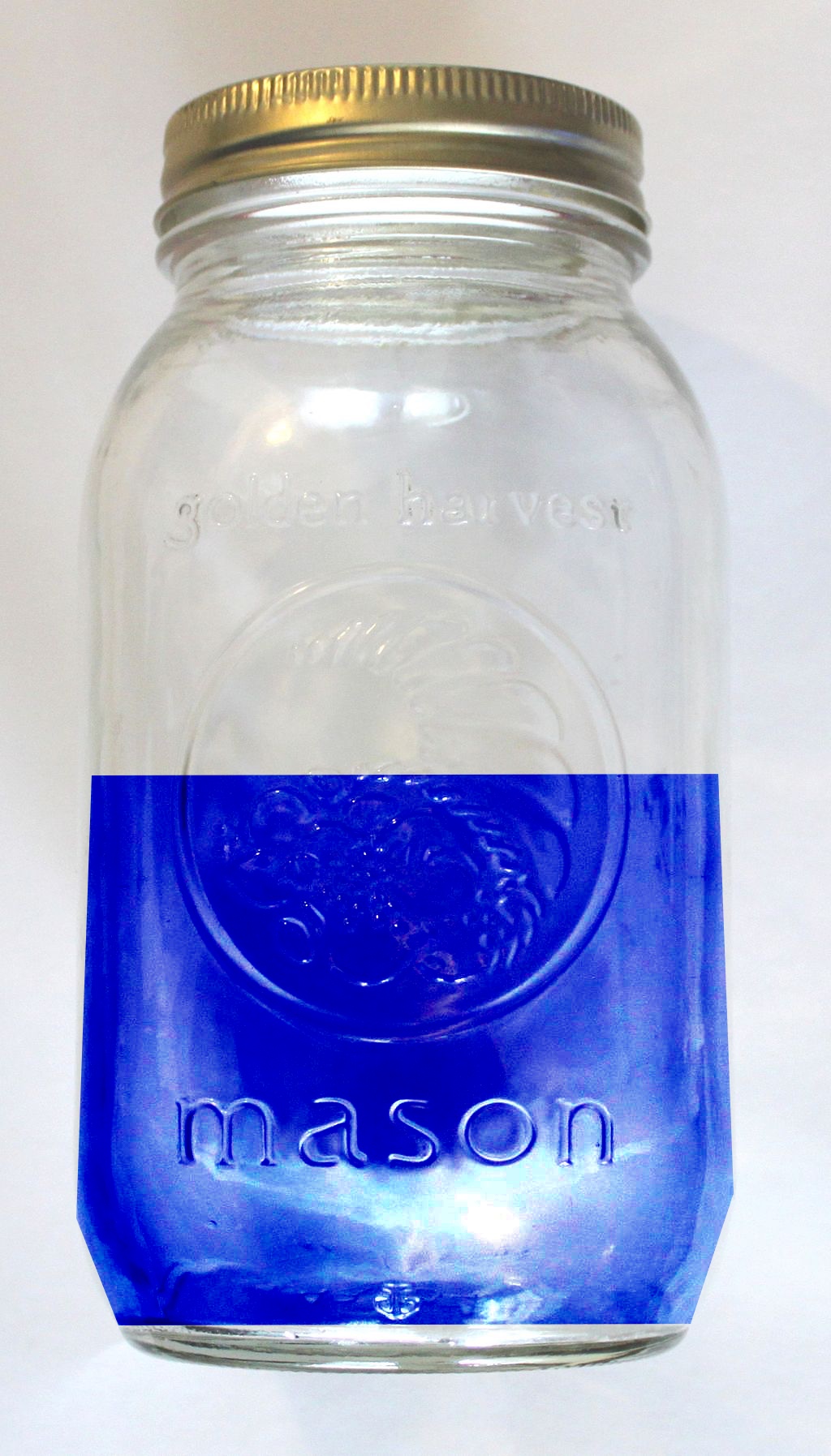
In this situation, even as late as the 53 minute mark, the jar is still only 1% full, but with the overflow coming in just seven minutes.
What would happen to you, as a scientist, if you said at the 53 minute mark, with the jar 1% full, that we needed a new jar immediately, and that the jar needed to be orders of magnitude bigger than the jar you already had.
Sounds like a hard sell. Up to the 53 minute mark it’s hard to tell the difference between linear and exponential growth, and skeptical colleagues might warn against the cost of bigger and more costly containment mechanisms when the jar is only 1% full.

I think this happens on a lot of projects. And I say this as somebody who loves simple solutions and generally is the person arguing we don’t need the complex enterprisey thing yet. I still think that most projects, including my own, don’t deal well with what happens when the exponential nature of complexity starts to take over.
The techniques that you would use to manage a very large and complex project are a lot of extra work, and feel very unnecessary on a smaller project. There’s often a lot of social pressure to do things the the simpler way. You just feel silly recommending a fully isolated architecture when you are building the beginning of a new Rails app. Or you feel silly insisting on unit tests for problems that can clearly be managed with integration tests or without tests at all.
To be clear, some of this is good, overengineering is definitely a problem, so I’m not saying this is an easy issue. I’m just saying that when you say the phrase “we won’t need that until the future”, the future is likely to come sooner than you think.
On the team side, one thing that causes loss of context is “siloing”, where the knowledge about critical information is limited to a very small number of developers, often just one.
Siloing is similar to the amoeba problem in that the first steps toward it are hard to distinguish from just “doing the right thing”, and then it seems to overwhelm your team.
One day you are saying “Noel did the last money story, let him do the next one”, which seems perfectly reasonable, the next day you are saying “Oh, Noel has all the context on money”, which is a bit more of a red flag, and then you are saying “Noel has left the project, what now?”.
And again, the solution here feels like adding friction – it’s asking people to take time to share context, it’s assigning work to people who don’t already have all the context. It’s a hard thing to justify when you are on a deadline.
It’s hard to wrap this all up because I don’t really have a solution to the problem. I’m not sure anybody does.
What I want you to take from this is a way to understand how systems develop and how code becomes legacy:
- Hidden dependencies between parts of a code base are a huge indicator of risk.
- Complexity increases faster than you think – you likely have more hidden dependencies than you think you do.
- The hidden nature of dependencies happens in part because an increasingly limited number of people know about the context when the code was written.
Given those principles, I start to look for tools or processes that might at least directionally improve our ability to keep the complexity under control longer.
I think every situation is a little different, but some ideas worth considering might include:
- Take seriously the questions that new developers have on encountering the code. Make sure the answers to those questions are written down in some way that future developers can find them. (In a lot of teams, a new member’s first PR is updating the readme for getting started – like that, but for everything)
- Try to have people who are leaving your team do some sort of exit interview or written document of the things that only they might know.
- Pair programming and code review can both prevent siloing. So can doing code walkthroughs or demos. Maybe even record the code walkthroughs.
- Put documentation where it might get read, if something comes up in a PR discussion, maybe make it a code comment or part of the documentation.
- Make documentation an explicit part of feature development.
- Try to avoid having unused code in the codebase, this is really hard to do, but dead code adds complexity for no benefit.
- A side effect of a lot of abstract structures that handle certain kinds of complexity is that they tend to hide the relationships between systems. A pub/sub system for example, is great because the emitter of an event doesn’t need to know who is going to use that event. But for legacy purposes that flexibility is a problem, because it can be hard to track down the effects of changes. There’s an extra responsibility for documentation here.
- Testing can be your friend here, but if you do it half-way, you will only get more legacy code – tests that fail for no obvious reason.
Next time: the history of web development.